
- 2020-12-26
- ブログ
地名の研究 Ortsnamenanalyse (11)からの続きです
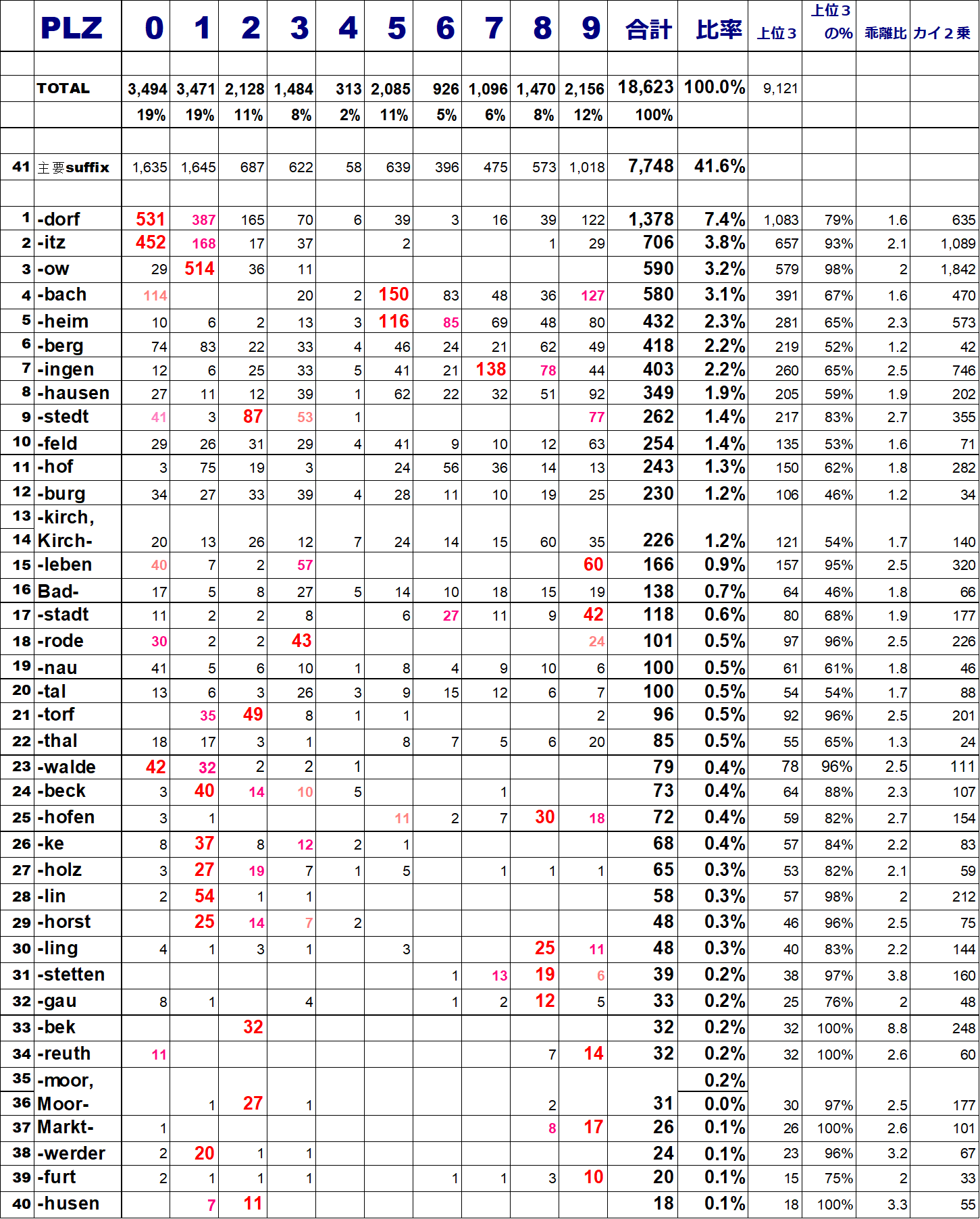
定量データを活用して、特徴的な地名suffixの分布を分類してきました。最後に纏めを書きます。
最初に書きましたが、このデータ解析を思いついたそもそもの動機は、最初にハンブルクに駐在し運転免許を取得して、車での休暇旅行を始めたころでした。
「ドイツの地名には -berg,-burg とか -dorf,-stadt 等が付く地名が多いとは誰もが感じることでしょう。また北ドイツに住んでいて南ドイツに旅行などすると妙に -heim,-ingen 等が付く地名が多いように感じられますし、また興味があって旧東独地域をドライブすると -ow,-itz 等が付く地名がやたら多くて、特に -ow 等はその語感・音の響きなどからも何となくスラヴ系の地名の名残なんだろうなということを感じます。地域によって地名にも偏りがありそうです。こういう『何となく...感じる』というのをもう少し定量的に表現できないものかと常々考えていました。」
最初の駐在の頃(1981~84年)なので、まだ IBMの ATなんて PCが普及する前のこと、Wikipediaで情報を検索なんて想像もできない時代、PLZも4桁で、東独は何重もの防護システムでガードされた別の国でした。

定量的な分析に着手できたのは、2度目の駐在(1987~92年)、それも東西ドイツが統一してからのことでした。ただ、東西の plzが統合ざれたのは 1993年のことなので、実際に地名のデータベースを手に入れて、マイクロソフトのリレーショナルデータベストソフト Accessにデータを取り込んで弄れるようになったのは3度目の駐在時(1996~98年)になってからのことです。今なら地名の由来や suffixの意味に関しては Wikipediaに潤沢に情報があり、想像や推測ではなく、もっと正確な分析ができたんだろうと思います。
ただ、やりたかったことは「個々の地名の由来に深入りする」前に、「何となくを定量化して、全体を俯瞰し傾向を掴む」ということでした。そこで仮説を持ったうえで、深入りして仮説を検証する・・・そういうことでした。今では多分無いと思われるドイツの電話番号簿の CD-ROMから PLZと紐づけされた地名のデータベースを抽出できたのはラッキーだったと思います。Googleで検索すると、個々の地名を入力すれば細かいデータを提示してくれるサイトはいくつか見つかりますが、データベース全体は入手が出来ないようです。(どなたか、それが可能ならご教示ください)。今回は話を簡単にするため、PLZの一桁目で分類してきましたが、より細かい地名のデータベースがあれば、PLZの二桁目と組み合わせることで、より明確な傾向値が見えてくると思います。
この手法の限界
基本的な欠陥は、大都市の中の細かい地名は、PLZがハンブルクやベルリンなどの下2桁で表されたりするので地名として登場しないこと。まあ、これは取り敢えずは仕方がないと割り切って(より詳細なデータベースが入手できれば解決可能)・・・
歴史的な経緯をすべて呑み込んだ「結果としての現在の地名」しか把握できないこと。政治的・人為的な改名も反映されてしまうこと。ゲルマン系の地名が付いていたところに、民族大移動でスラブ系民族がやってきて旧地名が一掃されスラブ系の地名になってしまうこと。音韻変化などでオリジナルの地名が変遷していくこと。また Chemnitzは、戦後は Karl-Maex-Stadtなんていう政治的な名前に人為的に改称された(その後、元に戻される)なんてことも反映されてしまいます。Fürstenbergが Eisenhüttenstadtと改称されたのもその類ですね。まあ、後者はそうたくさんのケースがあるわけでもないし、前二者もそういうことが起こったという痕跡が地名に表れていると思えば、受け入れるしかないんだろうと思います。
ということで、『何となく...感じる』というのをもう少し定量的に表現できないものか?という命題は概ね目標を達したと思いますので、今後はその仮説をもとに、ボチボチと個々の地名の深掘りをしていきたいと思います。
地名の研究 Ortsnamenanalyse (番外)に続きます。

























